Getting the right table design in Qlik is crucial to successfully delivering an application. Even more so if you’re developing on Qlik Sense and you want to fully embrace users creating their own visualizations.
In QlikView a bad data model was only seen by the developer so they could work around the complexity whereas in Qlik Sense users are fully reliant on you producing a data model that’s simple to understand and very forgiving when writing expressions.
Qlik automatically links tables together when there’s a field identically named. When users make selections in a field value both tables will effectively reduce down to show only the records associated with that selection when the linked field values match.
Qlik Sense has the ability to check field values when first loading the data and even if the field names don’t match Qlik Sense will make suggestions for you which is great news for new developers or developers that don’t want to get too bogged down with code.
Using this method you may find yourself with a data model which, on the face of it, works although there may be hidden challenges when you actually start to create your visualizations.
Here’s a simplified but common data challenge:

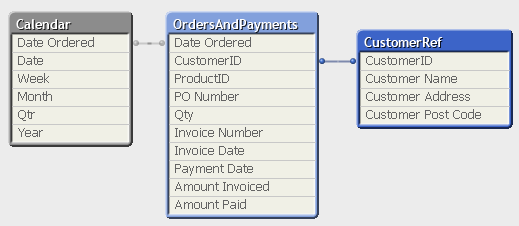
Qlik Data Challenge
In this data structure we have two reference tables:
- Calendar
- CustomerRef
And two Fact tables (tables that contain transactional data)
- Order
- Payments
At a glance this looks okay, we don’t have any nasty synthetic keys or loops within our model although I see two issues with it.
- If the users selects a dates from the calendar and did a sum on Amount Paid they may expect to see all the amounts paid for that time period although this isn’t the case. What they will be seeing is amounts paid for items ordered in that period regardless of when it was paid.
- If we take the assumption this is a large company with lots or orders then the two tables Calendar and Payments have to bridge the table Orders in order to make the calculation. From a performance point of view you will notice an increase in calculation time if you ‘cross’ a table which has more the 10k records in it.
What was can do here is bring the Order and Payment together into a single table, there are two ways to do this each with their own set of additional challenges.
Joining
If PO Number was distinct on both tables (one to one relationship) we could join them. On the face of it a good solution although we’d still have two date fields we want to join to a single calendar table (I’ve written a post on the types of joins you can use here). We would now need a link table to bridge the gap.
Qlik Joining Tables
A link table would use a Key field in the OrdersAndPayments table and load this into a new table with the Invoice Date and then do the whole thing again with the Date Ordered:

Qlik Link Table
This would create a Link table which means if they selected the 1st of November 2016 they would see results for both orders and sales for that date.

Qlik Link Table
Concatenation
Concatenation stacks one table on top of the other and will share column names when the fields are identically named.
Old school database developers will not instinctively like this approach as you’ll get a lot of null values within the table where the field name only belongs to one of the original tables, they would see this as very inefficient although Qlik doesn’t mind this approach and having lots of null values is absolutely fine from a performance point of view.
During the concatenation process we would have to create a new field in both tables that are identically named, one aliasing the Date Ordered field and one aliasing the Invoice Date field.

Qlik Table Concatenation Script
Below is what the table would look like if we were to simply concatenate it, As you can see CustomerID would be a problem if we did it this way and we would need that information populated:
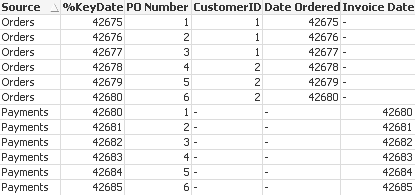
concatenate table view
We can expand the code to resolve the CustomerID issue, below I use the applymap function to find the CustomerID that belongs to the PO number.

Qlik Applymap Function
The NewConcatTable now includes the CustomerID for all records as shown below:

concatenate table view
We can then link the calendar off the new %KeyDate field.
Note – I’ll often use a % symbol before fields I don’t want the user to see, using the hideprefix function within the script they will be hidden from view.

Qlik Concatenation
Conclusion
So which way is best? Well as you can see they both have their pro’s and con’s.
The best solution is always that which works with your customers’ needs now and into the future. It’s really important when you’re developing a data model to speak with your customers and find out what questions they’re likely to ask of the data.
Joining data is great if you want to do calculation across two fields (that live in two separate tables) in the script. Although duplicated linking fields will explode the data given you strange results.
Concatenation is the usually the simplest way to join two or more fact table together although, as you’ve seen, you lose some of the associative power of Qlik.
Being able to adjust the data model into something usable is an important skill and very worthwhile and satisfying once you’ve got the hang of it (I’m still very much learning)
Richard

Pingback: Joins, Concatenation and the Applymap function | qlikcentral·
Pingback: Think Before You Link | qlikcentral·
Great post Richard. There are so many points to be made on this topic and there seem to be many schools of thought on this including a great one from Henric Crostrom: https://community.qlik.com/blogs/qlikviewdesignblog/2012/10/26/mixed-granularity
Which to say this topic is difficult to tackle because even developers like you and I still have uncertainty over how to build the most performant data model.
LikeLike
Pingback: 5 Qlik blogs you should check out | OptimalBI·
Pingback: The Best of 2016 Qlik Blog Posts « Learn Qlikview·
Pingback: 19 Tips All QlikView Beginners Must Know·