Hi everyone,
Understanding how the QlikView engine stores and processes the data really helps you create efficient QlikView dashboards. Understandably a Qlik developer never needs to know all the detail of exactly what’s going on under the hood although hopefully this post will be both informative and insightful to you.
In this blog post I will cover how data is stored within QlikView and how calculations are processed. Knowing this helps you to create data loads that consume less resources and makes your calculations run faster! Although I had a basic understanding of these concepts, for example Distinct values are good, I didn’t know the full detail of why until I met with HIC. These linked posts (there will be 3 in total) are a summary of the information he passed on.
The Qlik Engine is split into several parts which handle different aspects of the dashboard:

The Qlik Engine – With the data flowing in from the left the process run’s from the Script Engine clockwise.
When you load data into QlikView (from any source) you will see the table within the table viewer as you’d expect it to look, the same way the data looked before you imported it. Rows of data with the field values as per the original source.
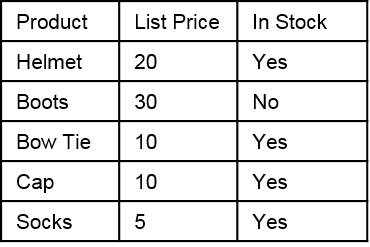
QlikView Data Load
Here we have a basic table. Three columns (or fields) and five rows of data.
Within the QlikView data engine the data has been transformed in the background, out of sight, and actually the data is storred in four separate tables. One Data and three Symbol tables:
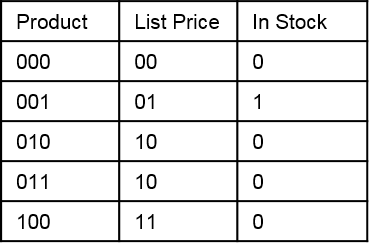
QlikView Data Table
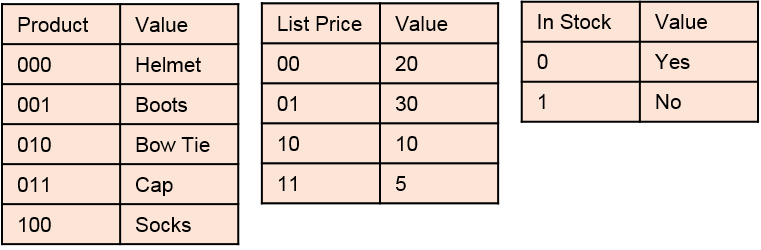
QlikView Symbol Tables
The Data table is now compressed because the values have been changed to “Bit Pointers” which lookup the original values from the three Symbol Tables. This makes data storage and retrieval very efficient and is the reason why QVD files are so much smaller than the original source data.
Because QlikView stores its data this way we, as developers, have to be aware of distinct and non-distinct field values.
For example Timestamps; when the data is loaded we need to ask the question, “Do we need the timestamp or just the date?”. If we just need a date its very simple within QlikView to Floor() the value within the data load which will remove the time element. This will reduce the number of distinct values and thus reduce the size of your symbol table. Which can’t be a bad thing!
If you do need the time then it would be best to split the field into two columns. One for date and one for time. Again with the new time column do you really need seconds? You can reduce that Symbol tbale size by simply removing these unneeded decimal places; Time(Floor (Time ,1/24/60) , ‘hh:mm’)
Even more can be done by removing Keys and ID’s that are no longer need. In fact any field that’s not required should be dropped as a matter of course…..
Hopefully you found this interesting,
I’m going to create more posts covering the Qlik Engine so please keep an eye out for those and I would love to hear your comments.
Happy Qliking!
Richard

Pingback: QlikDevGroup – Update | qlikcentral·
Pingback: Selections and Logical Inference | qlikcentral·
Pingback: How does Set Analysis Work in QlikView | qlikcentral·
Good post and a nice reminder to get rid of the junk you don’t need in your apps.
LikeLike