For years QlikView developers have been inserting a field into our Fact data tables and setting the value to 1.
1 AS %RowCount
It’s now very simple to Count the possible records by simply using Sum(%RowCount). Of course its just as simple to do Count(Field), as long as you know there will always by values populated then this is just as simple. Even simpler really as you don’t have to create another field within QlikView.
One of the myths about using a Sum rather then Count was that a Sum was more efficient. Henric Cronström dispelled this myth in his blog post A Myth About Count(distinct …).
Here is a chart from Henric’s post:
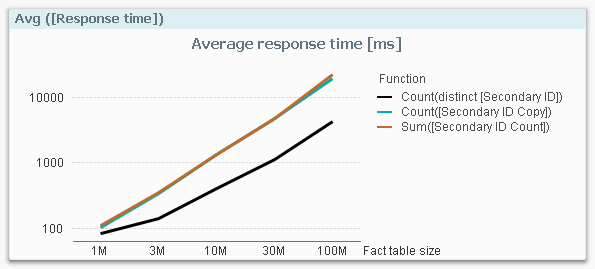
Henric QlikView Speed Results
You will notice that Count and Sum are performing equally. Since reading the post I started to change my ways until very recently.
The reason I’ve gone back to using Sum is because of aggregation within the Fact table. As a matter of course for large data sets there’s always a possibility that the data will become so large that, as a developer, you will ask the question, “Do you need that amount of history at that level of detail?”
To speed things up I’ll often put a break point in the data. Typically the latest three months are at a detailed level and the previous x months to that are aggregated. If this happens you can’t count the field anymore but you can still sum the %RowCount field.
I’d say to future proof your work using Sum is the best way to go.
I would love to hear your thoughts on this.
Thanks
Richard

Pingback: Qlik Sense Data Model and Field Naming | qlikcentral·