It doesn’t take long to discover that organising your data correctly within QlikView is the secret to success. A couple of well known phrases always spring to mind:
- The 80 / 20 rule; 80% of the effort goes into the data and 20% goes into the user interface
- Fail to prepare then prepare to fail
So these are clichés but let me explain. If your data is correctly structured then creating user interface objects in the Qlik front end becomes simple. You can easily add and modify objects and expressions to get the best out of the data.
Compare that to badly structured data. Yes it’s very easy to import several tables linking them with shared field names dropping fields to stop synthetic keys and loops. Hey presto within five minutes you’re off creating objects!!! Woo hoo!!
You start to discover expressions aren’t working as expected, suddenly you’re stuck on a problem which should be very simple and all the time you saved importing the data is lost.
If your data looks that this you may find developing the front end expressions and objects a challenge.
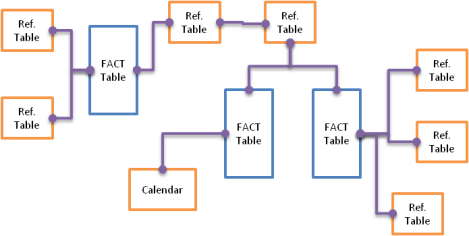
QlikView Snowflake
Referred to as a snowflake schema this is my starting point (but certainly not the final structure). From here I will make decisions on how best to transform the data within QlikView, I can create some basic calculations which also help to ensure the data is transformed correctly (so the results don’t change).
Here we have joined the three fact tables into one. Reference tables may also be joined to each other or the fact table leaving us with a simplistic design.
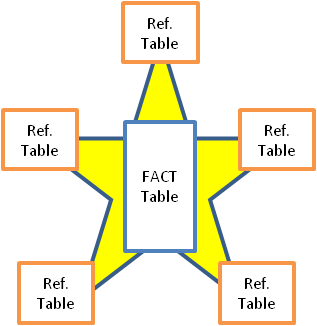
QlikView Star
Why do we do this?
To help the associative data model is one answer. In the snowflake schema shown earlier if a date is selected by the user you’re relying on data within the first fact table to create a link to the others. Which may not be the ideal solution.
Performance is another reason. Henric Cronström talks here about calculating field across table joins A Myth About Count(distinct …)
The moral of the story is the more QlikView has to jump between tables whilst performing a calculation the more effort is required.
So why not just have one table I hear you ask?
Good question. It’s all about getting the balance between memory and CPU right.
For very small application it’s probably not going to be an issue. So as you develop it makes sense to keep your reference tables split from the main fact for clarity on the data structure.
Once your application starts getting larger you may find optimisation becomes a priority. It’s at this point you can decide when to start joining more reference data to the main fact table.
The basic rule of thumb is:
· A single large table consumes a lot of ram.
· A snowflake schema response time can be slow as QlikView has to do more hard work.
· A star scheme is a happy balance (but not perfect)
Because it’s simple to view, use and develop further the star scheme is the one I work with in my application developments.
To develop a star Schema within QlikView first determine your data sources and identify which are fact tables and which are reference tables. Typically fact tables hold transitional data historically over time; reference tables hold hierarchies and are usually much smaller.
Look at each fact table in turn and ensure you fully understand the data.
· Is there a unique key?
· How is it linked (I.e. one to one / one to many)?
· Do you need all the data?
Once you have an understanding you can start to link data to the main fact using joins or applymap
Repeat the process for all your fact tables and concatenate them together. You’ll end up with a FACT table structured like the one below.

QlikView FACT Table
We created shared fields by naming them consistently and have the factual fields from each table. I call this the Battenberg table.

Battenberg
This design works well for QlikView. Shared fields would typically link to reference tables within the data structure or would be themselves dimensions.

Good post mate.
LikeLike
Pingback: Joins, Concatenation and the Applymap function | qlikcentral·
Pingback: A Common QlikView Data Structure Mistake | qlikcentral·
So which is the best star or snow flake schema ?
LikeLike
Hi Sunilkumar.
I tend to always develop a star schema but for speed and if you’re using small data sizes there’s nothing wrong with any type (star schema’ work better with large data volumes).
My new blog https://qlikcentral.com/2015/04/13/a-common-qlikview-data-structure-mistake/ gives more information about how a bad design can cause you issues.
Regards.
Richard
LikeLike
Pingback: Moving Forward With Qlik Sense | qlikcentral·
Pingback: Think Before You Link | qlikcentral·
Nice article, well explained.
LikeLiked by 1 person